
در کامپیوتر همه چیز به صورت صفر و یک است. برای اینکه بتوان کاراکترهای مختلف را در کامپیوتر ذخیره کرد؛ باید به ازای هر کاراکتر یک کد عددی در نظر گرفت. و با آن عدد در کامپیوتر کار کرد. به لیست کاراکترها و کدهای مربوطه، اصطلاحاً انکدینگ کاراکتر (Character Encoding) میگویند.
برای این کار استانداردهای بسیاری وجود دارد. از جمله:
- ASCII
- UTF-8
اَسکی (ASCII)
اَسکی (ASCII) اولین استاندارد انکدینگ است که در سال ۱۹۶۰ بر اساس کد مورس عرضه شد. اسکی، یک کد ۷ بیتی است که ۱۲۸ کاراکتر را شامل میشود. ۳۲ کد اول کاراکترهای کنترل (چاپ) هستند. و از کد ۳۲ تا ۱۲۷، نمادها، اعداد و حروف الفبای انگلیسی بزرگ و کوچک را در برمیگیرد.

Windows-1256
همانگونه که مشاهده میکنید، کد اسکی ۷ بیتی، زبانهای غیر انگلیسی را پشتیبانی نمیکند. برای حل این مشکل، یک بیت به آن اضافه کردند و یک کد ۸ بیتی (برابر با یک بایت) ساختند. به این صورت تعداد کدها دو برابر شد. و میتواند کد ۱۲۸ تا ۲۵۵ برای کاراکترهای زبان دوم (غیر انگلیسی) استفاده گردد. روشن است که کد ۸ بیتی، بیش از یک زبان غیر انگلیسی را نمیتواند پشتیبانی کند. به همین دلیل برای هر زبان یک جدول جداگانه وجود دارد. که اصطلاحاً به آن کدپیج (Code Page) آن زبان میگویند.
متأسفانه به دلیل آنکه به موقع از طرف ایران یک استاندارد واحد ارائه نشد، شرکتهای مختلف (مثل IBM و Microsoft و HP و …) کدپیجهای متفاوتی ارائه کردند. و این باعث شد فایلها و محتواهایی که با هر کدام ساخته میشد با دیگری قابل خواندن نباشد. به هر حال معروفترین آنها Windows-1256 است که شرکت مایکروسافت برای زبان عربی ساخته بود. بعداً با تغییرات اندکی کاراکترهای فارسی را هم به آن افزود. ولی به دلیل آنکه حروف ویژه فارسی، در جای درست خود نیست؛ مشکلات بسیاری را ایجاد میکند. (مثلا در سورت الفبایی)
یونیکد (Unicode)
در سال ۱۹۸۰ استاندارد یونیکد معرفی شد. در این استاندارد برای هر کاراکتر در هر زبان یک کد یکتا اختصاص داده شد. حتی نمادها و ایموجی ها نیز کد اختصاصی خود را دارند. به هر عددی که نماینده یک کاراکتر است کدپوینت Code Point میگویند. در استاندارد یونیکد، بیش از یک میلیون کاراکتر تعریف شده است. بیشتر این عدد را در مبنای ۱۶ (هکزادسیمال) نمایش میدهند. مثل U+FF03
برای آگاهی بیشتر unicode.org را ببینید.
تایپ کاراکترهای یونیکد
برای بسیاری از کارکترهای یونیکد، کلیدی روی کیبرد وجود ندارد؛ برای وارد کردن آنها، ابتدا دکمه Ctrl + Shift + U را فشار دهید، سپس کدپوینت آن کاراکتر را تایپ کنید و در پایان کلید Space یا Enter را بزنید.
اگر برخی از کاراکترها را زیاد استفاده میکنید؛ بهتر است که کدپوینت آنها را حفظ کنید تا بتوانید سریع آنها را وارد کنید.
روشهای ذخیره یونیکد
برای ذخیره کردن کدپوینت در فایل چند روش وجود دارد:
- UTF-8
- UTF-16
- UTF-32
- …
UTF-8
مطمئناً محبوبترین آنها UTF-8 است. چون در بیش از ۹۰٪ سایتهای اینترنتی از آن استفاده میشود.
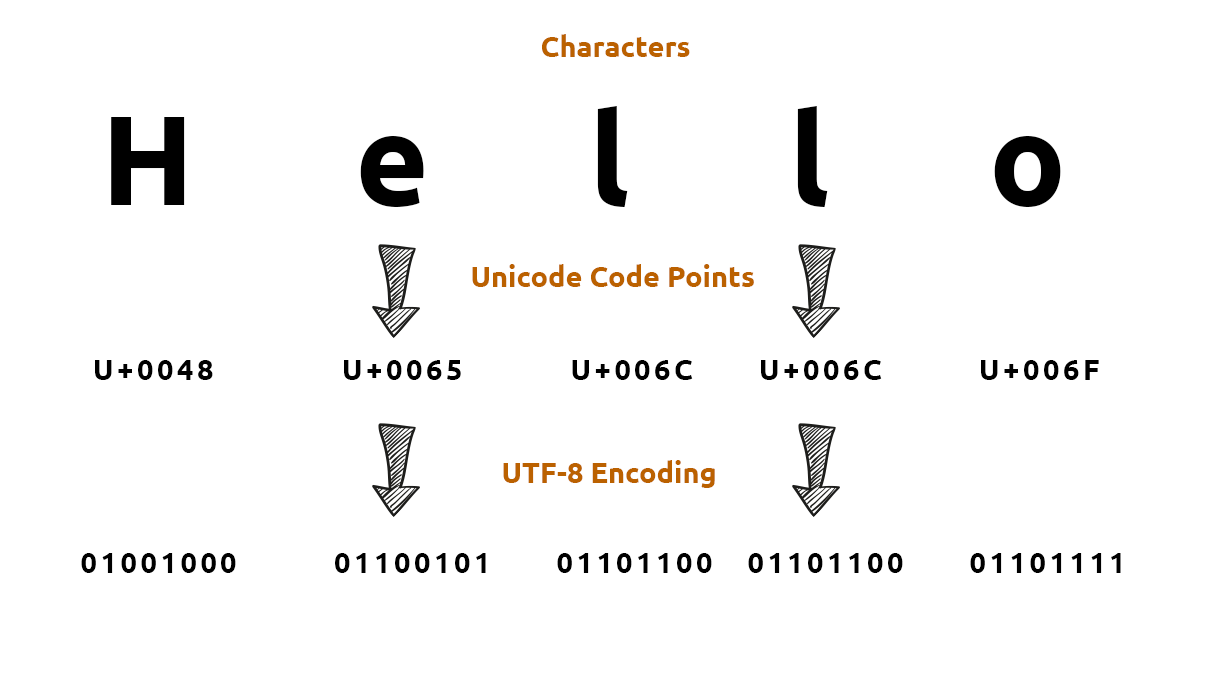
در UTF-8 طول هر کاراکتر، متغیر است و میتواند بین یک تا چهار بایت را اشغال کند. تعداد یکهای بایت اول با تعداد بایتهای هر کاراکتر برابر است. بایتهای بعدی همه با 10 آغاز میشود.
| First | Last | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|---|
| U+0000 | U+007F | 0xxxxxxx | |||
| U+0080 | U+07FF | 110xxxxx | 10xxxxxx | ||
| U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| U+10000 | U+10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
انواع UTF-8
برای ثبت کاراکترهای زبانهای مختلف ماکزیمم ۳ بایت کافیست؛ و بایت چهارم بیشتر برای ایموجیها و … به کار میرود.
- utf8mb3: ماکزیمم بایت ۳
- utf8mb4: ماکزیمم بایت ۴
در برخی از نرمافزارها مثل MySQL اگر UTF-8 را انتخاب کنید به صورت utf8mb3 در نظر گرفته میشود و ایموجیها را نمیتوانید ذخیره کنید. پس در صورت نیاز باید حتما utf8mb4 را انتخاب کنید.
Byte Order Mark (BOM)
علامت مشخص کننده ترتیب بایتها (BOM)، ۲ تا ۴ بایت در ابتدای فایل متنی است که نوع انکدینگ فایل را تعیین میکند. برای مثال در UTF-8 مقدار آن ۳ بایت (EF BB BF) است. همه نرمافزارهای ویرایش متن این مقدار را به صورت پیش فرض، در ابتدای فایل میافزایند. البته به طور کلی BOM اختیاری است و میتوان آن را از ابتدای فایل حذف کرد.
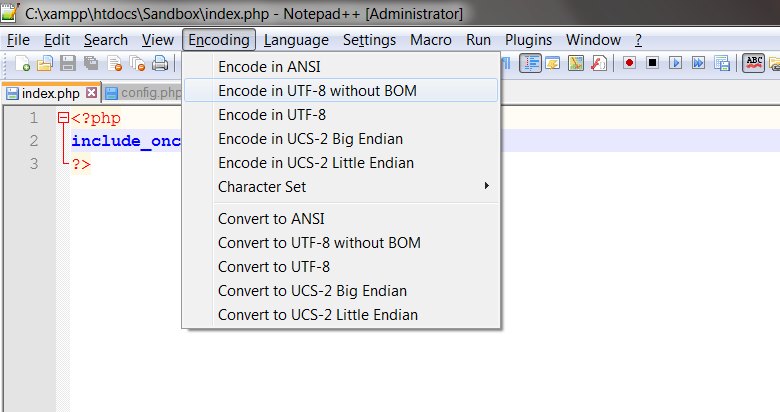
گاهی، وجود BOM در برنامه نویسی مشکل ایجاد میکند؛ و باید آن را حذف کرد.


